사전 요구 사항: Python
1. 자바 설치
1) 자바 다운로드 및 경로 지정
https://www.oracle.com/in/java/technologies/downloads/
D:\jdk-21.0.2
2) 시스템 변수 편집 (JAVA_HOME)
시스템 환경 변수 편집 -> 시스템 변수 새로 만들기

3) Path 편집 (시스템 환경 변수에서 Path 내에 %JAVA_HOME%\bin 추가)


4) java 정상 설치 여부 확인 (java -version)

2. Pyspark 설치
https://spark.apache.org/downloads.html
1) 스파크 다운로드 및 경로 지정
https://www.oracle.com/in/java/technologies/downloads/
D:\spark-3.5.0-bin-hadoop3
2) 시스템 변수 편집 (SPARK_HOME)

3) Hadoop (winutils.exe) 다운로드 및 경로 지정
https://github.com/cdarlint/winutils/tree/master
D:\hadoop-3.3.5
4) 시스템 변수 편집 (HADOOP_HOME)

5) Path 편집 (%SPARK_HOME%\bin; %HADOOP_HOME%\bin 추가

6) pyspark 정상 설치 여부 확인 (pyspark)

Pyspark 예시 코드 (Python 실행 후)
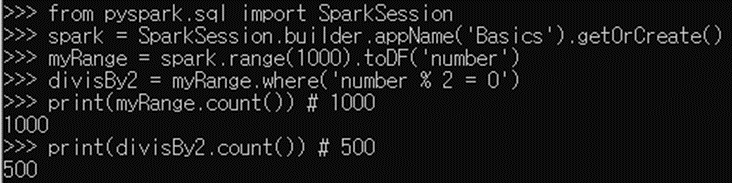
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('Basics').getOrCreate()
myRange = spark.range(1000).toDF('number')
divisBy2 = myRange.where('number % 2 = 0')
print(myRange.count()) # 1000
print(divisBy2.count()) # 500'Data Engineering' 카테고리의 다른 글
| 데이터 거버넌스(Data Governance) (0) | 2025.05.01 |
|---|---|
| 데이터 파이프라인(Data Pipeline) (0) | 2025.04.01 |
| 데이터 레이크(Data Lake) (0) | 2025.03.02 |
| Apache Spark 기본 정리 (0) | 2024.03.15 |
| Apache Hive 정리 (0) | 2024.01.14 |


