Bias: 데이터의 특징을 필요 이하로 추출할 때 나타납니다. -> 클수록 Underfitting
Variance: 데이터의 특징을 필요 이상으로 추출할 때 나타납니다. -> 클수록 Overfitting
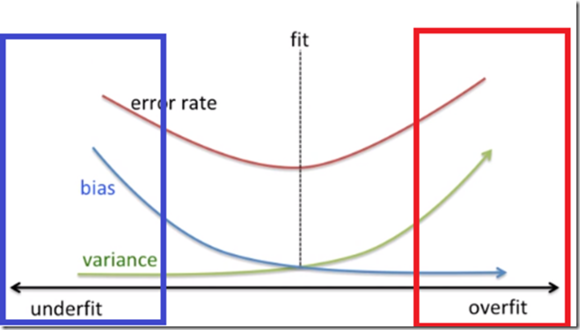
Bias를 지나치게 줄이고 Variance를 높이면 Train data에서만 모델이 잘 학습되는 경향이 나타나게 됩니다.
반대의 경우엔 데이터의 특징이 뭔지를 모델이 찾아 내지 못할 수 있습니다.
즉, Bias와 Variance의 중간값이 가장 좋은 모델 조건이 된다고 볼 수 있습니다.
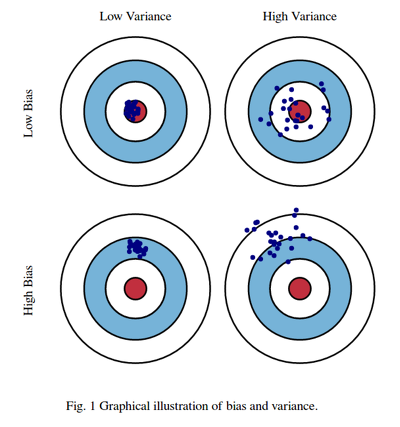
(Bias는 정답과 예측값 간의 거리, Variance는 모델별 예측값 간의 거리)
Overfitting 피하는 방법: 더 많은 데이터를 확보, 부족학 학습 데이터 채우기, 학습에 사용된 특징 줄이기, 특징들의 수치값 정규화 (특정 특징에 의한 편향 줄이기)
예시 (출처: 나의 첫 머신러닝/딥러닝 저자: 허민석)
Underfitting의 예
| 사물 | 분류값 | 생김새 |
| 야구공 | 공 | 동그라미 |
| 농구공 | 공 | 동그라미 |
| 테니스공 | 공 | 동그라미 |
| 딸기 | 과일 | 세모 |
| 포도알 | 과일 | 동그라미 |
데이터의 특징이라곤 생김새밖에 없으므로 (충분하지 못한 특징) 데이터의 bias 발생 => underfitting이 되어버렸습니다.
Overfitting의 예
| 사물 | 분류값 | 생김새 | 크기 | 줄무늬 |
| 야구공 | 공 | 동그라미 | 중간 | 있음 |
| 농구공 | 공 | 동그라미 | 큼 | 있음 |
| 테니스공 | 공 | 동그라미 | 중간 | 있음 |
| 딸기 | 과일 | 세모 | 중간 | 없음 |
| 포도알 | 과일 | 동그라미 | 작음 | 없음 |
위 Train 데이터에선 생긴새가 동그라미이고, 크기가 작지 않으며 줄무늬가 있으면 공이다라고 기계가 인식하게 됩니다.
| 사물 | 분류값 | 생김새 | 크기 | 줄무늬 |
| 골프공 | 공 | 동그라미 | 작음 | 없음 |
| 수박 | 과일 | 동그라미 | 큼 | 있음 |
| 당구공 | 공 | 동그라미 | 중간 | 없음 |
| 럭비공 | 과일 | 타원형 | 큼 | 있음 |
| 볼링공 | 공 | 동그라미 | 큼 | 없음 |
그러나 위 Test 데이터에선 크기가 작지 않으며 줄무늬가 있는 경우는 과일밖에 없으므로 정확도가 0%가 나옵니다. => 특징이 필요 이상으로 많은 경우 (분산이 높은 경우) Overfitting이 됩니다.
'ML&DL' 카테고리의 다른 글
| 앙상블 학습 (Ensemble Learning) 1 - 배깅 (Bagging) (0) | 2024.08.09 |
|---|---|
| 머신러닝 회귀 모델 (Regression Model) 평가 지표 (0) | 2021.07.17 |
| 기초적인 회귀 (Regression) 예측 모델 생성 (0) | 2021.07.11 |
| [머신러닝] K-NN (K-Nearest Neighbors) (0) | 2021.07.03 |
| 머신러닝 용어집 - A (0) | 2021.06.30 |


